
What is Web Scraping?
Are you curious about web scraping and how it can help you get the data you need? Do you want to learn more about how to use automated processes for gathering online data? If so, then this blog post is for you! Here we’ll explain what web scraping is, the benefits of using it, and some tips on how to get started.
What is Web Scraping?
Web scraping is a process used to extract data from websites. It involves using a computer program to automatically make requests to websites, collect and process the information, and then store it in a structured format for later use. Web scraping is used to collect large amounts of data that can then be used for analysis, research, and other purposes. It is an efficient way to extract data from webpages, as it can be done quickly and cheaply. Additionally, web scraping can be used to monitor changes on webpages and alert users when new content is available. Web scraping is an important tool for data scientists and researchers, as it allows them to easily access and analyze large amounts of data on the web.
Benefits of Web Scraping
Web scraping provides businesses with the ability to quickly and easily acquire data from a range of sources. This data can be used for a variety of purposes, such as providing insights into customer trends and preferences, monitoring competitors’ activities, and analysing changes in market conditions.
Using web scraping, businesses can stay ahead of their competition by gathering data quickly and accurately. By using web scrapers, businesses can monitor their competitors’ websites to see what new products they are launching, how they are pricing products and other important information. This allows businesses to make timely decisions, such as pricing their own products competitively or launching new products before their competitors do.
Web scraping also makes it easier for businesses to collect customer feedback. By using web scrapers, businesses can quickly and easily gather reviews and comments from customers about their products or services. This allows them to identify areas for improvement and create better customer experiences.
In addition, web scraping helps businesses save time and money by automating data collection. This eliminates the need for manual data entry and allows businesses to focus their resources on more important tasks. Web scraping also helps businesses save time by allowing them to extract data from multiple sources in one go, rather than manually searching multiple sources for the same data. Overall, web scraping provides many benefits that make it an invaluable tool for businesses of all sizes.
Risks and Challenges of Web Scraping
Web scraping has a range of risks and challenges associated with it. The most prominent of these is getting blocked by the website, which mainly depends on the size of your operation. If you send out too many requests per second, it can alert the server that your web scraping bot is accessing the website too quickly. This can lead to your IP being blocked from accessing the website.
Other risks include getting caught in a captcha loop, where the website has set up a captcha test to ensure that the visitor is human. If a web scraping bot fails this test multiple times, it can get caught in an endless loop and will be unable to access the website.
Structural changes to the website can also be a challenge for web scraping bots. If the website changes its structure, the bot may no longer be able to access the data it needs. This means that web scrapers must continually monitor and update their bots when websites change their structure.
Finally, there are legal implications associated with web scraping. It is important to be aware of any laws or regulations that may apply to web scraping in your particular jurisdiction. In some cases, taking data from certain websites without permission may be illegal.
Techniques Used for Web Scraping
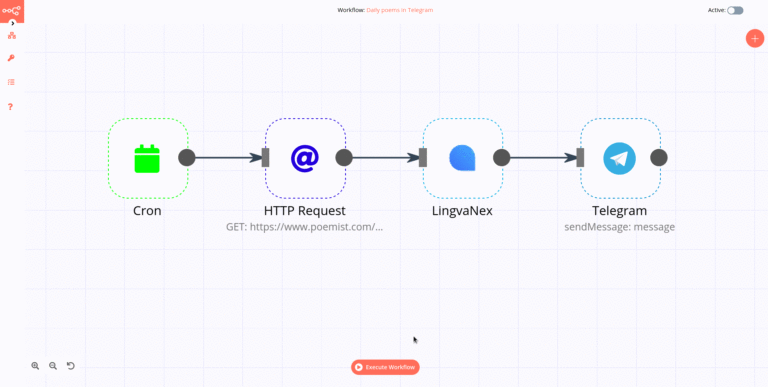
Web scraping is an automated process of extracting large amounts of data from websites. To do this, web scrapers use different techniques and methods. The most common method of web scraping is through the use of bots or crawlers which are software programs designed to crawl through websites and collect data. These bots can be programmed to crawl through multiple websites and collect the desired data. Another technique used for web scraping is DOM (Document Object Model) parsing which enables the scraper to view the structure of a website in depth. This method is often used for dynamic sites as it allows the scraper to extract data from specific elements on the page. Additionally, scrapers may use APIs (Application Programming Interfaces) to access data quickly and efficiently without needing to crawl through multiple websites. Finally, scrapers may use captcha solving services to bypass captcha challenges when accessing certain websites. With these techniques, web scrapers can collect the desired data from any website.
Gathering Data from Websites
Web scraping is the process of collecting data from a website using an automated script. The script follows certain rules and instructions to scrape the data from websites. This data can be collected from HTML, XML, JSON or any other source. The data can then be converted into structured data such as a spreadsheet or a database for further analysis.
The scripts used for web scraping can be programmed to extract specific content from websites. This can include text, images, links, and other types of information. Web scraping is used to gather large amounts of data quickly and accurately without having to manually enter it into a database or spreadsheet. It is also possible to scrape data from multiple websites in one go, making it a very useful tool for researchers and marketers.
Web scraping also has the potential to speed up processes that would otherwise take a long time to complete. For example, by automating the process of collecting competitor prices, businesses can save time and money. Additionally, web scraping is used in many industries such as finance, retail, healthcare and more, to gain insights into the market and customer behavior.
The Legal Implications of Web Scraping
Web scraping has become an increasingly popular way of gathering data from websites, but it is important to be aware of the legal implications. Web scraping activities can be seen as a form of data mining and can potentially infringe on a website’s terms of service or copyright. It is important to understand the legal implications before engaging in web scraping activities.
The laws governing web scraping largely depend on where the data is being sourced from and how it is being used. Data from public websites is typically not subject to copyright protection, so web scraping activities may be allowed in these circumstances. However, data from private websites or databases may be subject to copyright laws and must be taken into consideration. If the data being scraped is used for commercial purposes, it may also be subject to fair use laws which protect against certain uses of copyrighted content.
When scraping public websites, it is important to adhere to the terms of service outlined by the website. Many websites prohibit the use of bots or automated scraping tools and may take steps to prevent or limit access when they detect such activities. It is also important to consider the impact that web scraping may have on a website’s performance. If a website experiences an influx of automated scraping requests, it can affect its speed and ultimately lead to degraded performance for users.
Finally, web scrapers must also consider the use of captcha solving services when accessing protected websites. Captcha services are used to prevent automated scripts from accessing websites, so it is important to
Making Use Of Captcha Solving Services
Using a CAPTCHA solving service is one of the most effective ways to ensure your web scraping efforts are successful. CAPTCHAs (Completely Automated Public Turing Test to Tell Computers and Humans Apart) are used by websites to identify bots and humans, making it harder for web scrapers to access certain sites. Using a CAPTCHA solving service can help you bypass these restrictions, allowing you to gather the data you need.
A CAPTCHA solving service works by providing a service that can recognize and solve CAPTCHAs for you. They use sophisticated algorithms and powerful OCR technology to recognize the CAPTCHAs, making them much more reliable than manual methods. This allows you to automate the process of solving CAPTCHAs, ensuring that you can always get access to the data you need.
Using a CAPTCHA solving service also helps protect your web scraping efforts from malicious actors. By using a trusted service, you can make sure that your data is not being accessed by malicious bots or hackers. This helps protect your data and ensures that it remains secure.
Overall, using a CAPTCHA solving service is an essential part of any web scraping effort. By using a reliable service, you can ensure that your data is safe and secure while also being able to access the data you need quickly and efficiently.
Conclusion
Web scraping is a powerful tool which can be used to collect large amounts of data from the web quickly and accurately. It has many benefits, such as increased accuracy, increased efficiency and cost savings. However, it is important for users to be aware of the legal implications of web scraping, as well as potential risks, such as data privacy violations. Furthermore, it is important to be aware of the techniques used for web scraping, as well as captcha solving services which can help make web scraping easier. Ultimately, with web scraping, it is possible to collect large amounts of data from the web in a cost-effective and efficient manner.